
Google Summer Of Code Archive
As a part of Google Summer of Code program, I was supposed to write biweekly work updates, which kinda made by archives a bit of cluttered. So, one fine morning, I decided to compile all of them into a single post to clean things up. Doing it manually seemed daunting, so I decided to make a script which took me even more time :p
Anyways, the following post contains all my GSoC blog updates in chronological order. The final offical report for my GSoC project here and here.
PS: If you’re a GSoC aspirant, this post will give you a gist of what it’s like to go through the GSoC program, I’d also suggest you to read What “NOT” to expect from GSoC
Alright, here we go…
- My GSoC story begins
- Two weeks into Community Bonding
- GSoC Update- Mid of Phase 1
- GSoC Phase 1 Final Week
- Marking the end of Phase 1
- GSoC - Mid of phase 2
- GSoC - Final Week Of Phase 2
- GSoC - Mid of Phase 3
- GSoC- The final week!
My GSoC story begins My-GSoC-story-begins
Published on: 02 May 2017, Tue

:tada: That was the most exciting moment in past few months as I finally acheived my 2-year awaited GSoC dream. I started contributing to coala since the very first day of 2017 (Not a new year resolution though :P) and no doubt, the journey so far had been awesome and offered me a lot of opportunities to learn and grow as a developer. The last few months have indeed been bit hectic but the outcomes have been worth every effort.
About my project

You can read the abstract here
The road ahead
This month is officialy a “community-bonding-period”. As I’m already familiar with the community as well as the codebase of coala-quickstart, I plan to do extensive research about implementation of my project in this period so that I don’t face much difficulties during the upcoming “coding-phases”
PS: There’s gonna be lot of upcoming blog-posts regarding my GSoC journey and the new things that I learn on my way. Stay tuned…
Two weeks into Community Bonding
Published on: 20 May 2017, Sat
So it’s been more than two weeks into the Community bonding period, my examinations are about to get over (finally:sweat_smile:) and I’ve planned out my milestones with my mentors. Looks like I’ll be all set to code after 1 week.
Here’s what I was upto past two weeks:
- I introduced myself and my project on the mailing lists.
- Disucssed my projects with my mentors and made adjustments to my timline.
- Did some research on the meta-files and the information to work on during my first phase of the project.
- Created milestones and issues on Gitlab to keep track of my progress over the entire GSoC period.
- Proposed a cEP (coala Enhancement Proposal) regarding approach in Phase 1 of my project.
- Managed to get past my theory exams somehow :P , still left with Minor Project and Winter-training viva.
Some nice links:
- My post in mailing list - https://groups.google.com/forum/#!topic/coala-devel/0A_Wz3pyWgk
- The cEP I proposed - here
- Description of my project - http://projects.coala.io/#/projects?project=enhance_coala-quickstart
- My project milestones -
GSoC Update- Mid of Phase 1
Published on: 10 Jun 2017, Sat
Hey folks, hope everyone is doing great in this summer vaccation season. I saw statistics released from Google lately and was really happy to know that my university had the third highest number of GSoC students selected in the world :). Anyways, in this blog post I’ll summarize my work for these past two weeks.
TLDR;
Here’s what I was upto last two weeks.
- Implemented modules for representing information and extracting information.
- Created upstream issues for some of the things, would be probably working on them on my own if time allows (stretch goals)
- Added Appveyor continuous integration for windows.
- Added Travis CI on my project.
What’s next?
In the upcoming weeks, I’ll be working on writing extraction modules for extracting information of interest to coala from common kinds of meta-files. If you’re wondering what these files are, well they are:
package.jsonGruntfile.jsGulpfile.jsGemfile.editorconfig
A deeper dive into my work
These 2 weeks have been a good learning experience to me. I got to learn more about Object oriented functionalities in python and I explored the world of hosted Continuous Integration and Delivery platforms in-depth.
Week 1
The primary tasks for this week were to create a working prototype for the cEP (coala’s Enhancement Proposal) that I proposed. Having a cEP in advance made it easier for me to take design specific decisions (I’m kinda starting to like “plan well before implement” stuff approach as opposed to the Hackathon-like approaches where I just dived into implementation and the see where it ends up). I wrote extensive tests for both of my modules, namely Info and InfoExtctor. Another important decision that I had to make was the directory structure and location of these modules (should these go into coalib or just remain in quickstart). After discussion with my mentors we agreed upon keeping them in quickstart’s repo only.
I already made a PR for my Week 1 and I expect to get it merged soon.
Week 2
After weekly meeting of Week 1, we ended up modifying our proposed timeline. As suggested by one of the maintainers (John), we shifted the continuous Integration tasks from Phase 3 to Phase 1 and decided to push everything in the timeline downwards by 1 week. I believe that it was a good decision because it is better to catch and fix platform specific issues earlier during implementation rather than having them reported later (prevention is better than cure!).
So in the second week, I worked on adding Continuous Integration platforms Appveyor and Travis CI to coala-quickstart similar to other existing coala repositiories. It turned out to more reigorous and complicated than I expected and I ended up making around ~90 attempts to get all of them working at once (that’s probably due to my wrong approach of doing things the hit-and-trial way, I should have understood concepts first and then tried to build things from scratch, but nevermind, that’s how you learn :P). Finally I ended up making them work successfully and I’m very happy about it (earlier I used to shy away from issues related to CI but I don’t think now I’ll ever do that).
So after the first two weeks, I was able to set up a basic structure and CI system for my upcoming Tasks.
That’s all folks! Stay tuned for more updates…
GSoC Phase 1 Final Week
Published on: 23 Jun 2017, Fri
Hey everyone! I hope you all are having a fantastic summer. The first phase of my GSoC project is about to end, and I’ll be soon filling up my evaluation. In this post, I’ll summarize my progress (like I’ve been doing in all my previous posts :p). Okay so here it goes.
TLDR;
Here’s my progress since my last blog post (almost 2 weeks ago)
- Reiterated on Appveyor and Travis PRs and got them merged.
- Went through multiple iterations of my Info Extraction framework’s PR, implemented some new cool features and got the PR merged : tada:
- Extracted information from the files:
package.jsonGemfile.editorconfig
What’s next?
Phase 2, obviously! :P
As I pulled the Continuous Integration tasks from Phase 3 of my proposal to Phase 1, I had to push some of the tasks as stretch goals. I and my mentors will be discussing the future tasks to pursue in the upcoming weekly meeting, and we’ll adjust the timeline accordingly (don’t worry I’ll update everyone once we finalize the tasks :P)
The next Phase will majorly involve utilizing the information that I’ve been able to extract via my Info Extraction framework. It’s gonna be slightly tight as I’ve my campus placements upcoming (damn yes! days of anxiety are near) and I’ll have to prepare for them as well (fingers crossed :))
A deeper dive into my work
These two weeks, I underwent multiple iterations of my previous week’s work until they were in perfect shape (Oh yes, getting the code merged is much more exhausting than writing the code).
Travis and Appveyor
Finally, I was able to figure out the mysteries of Travis, CircleCI, and Appveyor. Now we have Travis, Circle CI, and Appveyor integrated into the coala-quickstart repository. This is a very useful step as I’ll be able to make sure my solution works flawlessly across different Operating Systems.
Here’s how the tree looks like now
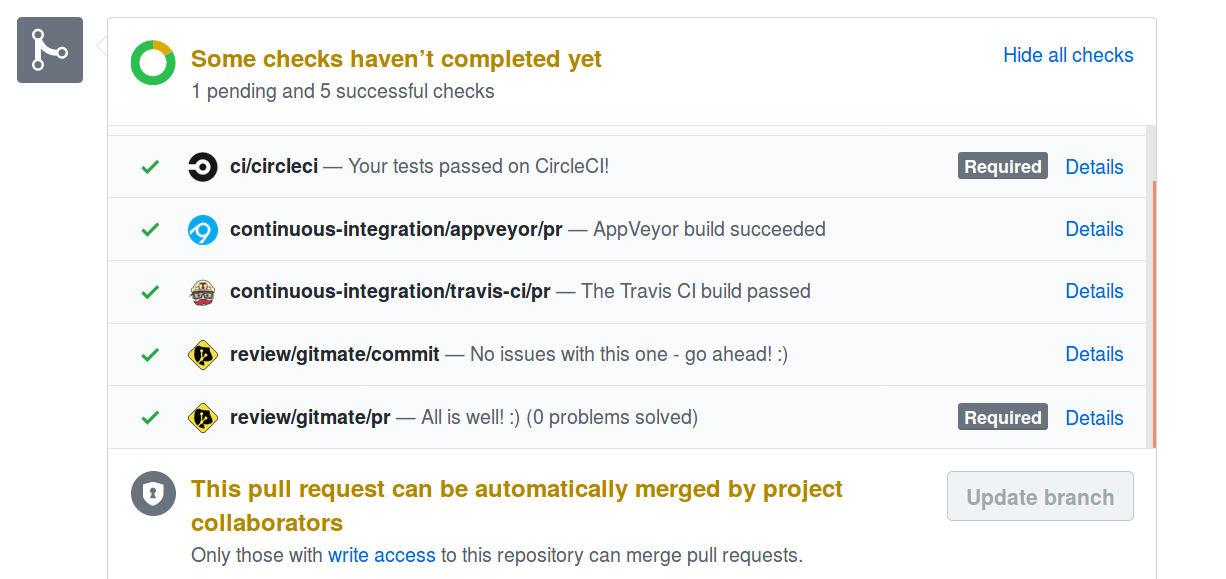
I remember when I joined this Open Source world I used to consider these CI checks as “annoying mystery systems”:sweat_smile:, but later I realized their importance and appreciate the services they offer for free to the open source projects.
It was disappointing the Travis builds for OSX took a crazy long time to start and I eventually ending up removing them from the configuration. I’m planning to try some other CI service for OSX if I finish early with my GSoC tasks.
Special thanks to John (@jayvdb) for helping me out with all this.
The Information Extraction Framework
After making several iterations to my basic version of cEP-0009, we ended up with a pretty robust module with some cool features, one of them being the “type signature” based information value validation. If you are wondering what that means, let me demonstrate with some examples:
def assert_type_signature(value, type_signature, argname):
"""
Validates the value with the type_signature recursively. The type
signature is either a single type object, or a collection of type
objects or allowed values or type signatures.
>>> assert_type_signature(3, int, "var")
True
>>> assert_type_signature(3, (3,), "var")
True
>>> assert_type_signature([3,4], ([int],), "var")
True
>>> assert_type_signature([3.0 ,4], ([int, float],), "var")
True
>>> assert_type_signature([3,4], ([1, 2, 3, 4],), "var")
True
>>> assert_type_signature(["foo", 420], [[str, int]], "var")
True
>>> assert_type_signature("tab", {"tab", "space"}, "var")
True
:param value: Object to be validated against ``type_signature``.
:param type_signature: Object that describes allowed types and values for
the ``value``.
"""
^^ I was bit lazy and ended up copy-pasting the inline documentation :P The main idea being it will be able to enforce constraints on the possible values an Info class can take in my framework. It’s very flexible, and you can give complicated type signatures like
type_signature = ([str, int, 9.5], "Hello", "coala!", [[classA], [int]])
Hmm, so let’s see what all values match the above type signature:
- 9.5
- [“some string”]
- [4, 5, “another string”]
- “Hello”
- [[4,2,1]]
And what doesn’t match
- “Foo”
- 5.7
- [2, 2.3]
- [[“some string”]]
Note: The outer tuple is just a container of multiple possible type signatures and has no role in type matching.
It was easy, isn’t it?
Okay, so after some iterations, I was finally able to get the concerned PR merged : tada:
Implementing InfoExtractor classes
For the first phase, the files we ended up picking were
- package.json
- Gemfile
- .editorconfig
After the implementation of the Information Extraction Framework, the only tasks that I need to focus on are:
- Parsing the file.
- Finding information from the parsed file.
Rest everything (locating files, storing information, validating information, validating filenames, representing information, etc.) is taken care by the
InfoandInfoExtractionclasses.
I was lucky to find the Gemfile parser on PyPI, but for .editorconfig We decided to make and use a custom parser derived from their “editorconfig-core-py” repository. Somehow I was able to make everything work together and make PRs of all three of them in a good-shape.
That’s all folks! I’m not gonna bore you guys more (brevity is a dying art :P). Stay tuned for more updates…
Marking the end of Phase 1
Published on: 26 Jun 2017, Mon
So the first phase is finally over, and I managed to complete all my tasks in time :tada:, I’m a 1/3rd GSoCer now. Excited, as always, I filled up my First Evaluation on Google Summer Of Code’s site, and probably my mentors have completed theirs as well (I had to write four long 2k word size answers in the evaluation form :P)
Thanks a ton to my mentors Adhityaa and Adrian for helping me with my doubts in the weekly meetings, and reviewing and merging all my stuff. The meetings were fun (yeah, some sarcastic jokes when both of them were around :P) as well as informative. It helped all of us align on the same page at the end of every week. This week I had a quite rigorous discussion with Adhityaa regarding future tasks which went on till 2 hrs.
Also, credits to finish my tasks in time goes to the admins who kept us pushing to complete all our milestones in time.
After phase 1, this is how my burndown chart looks like
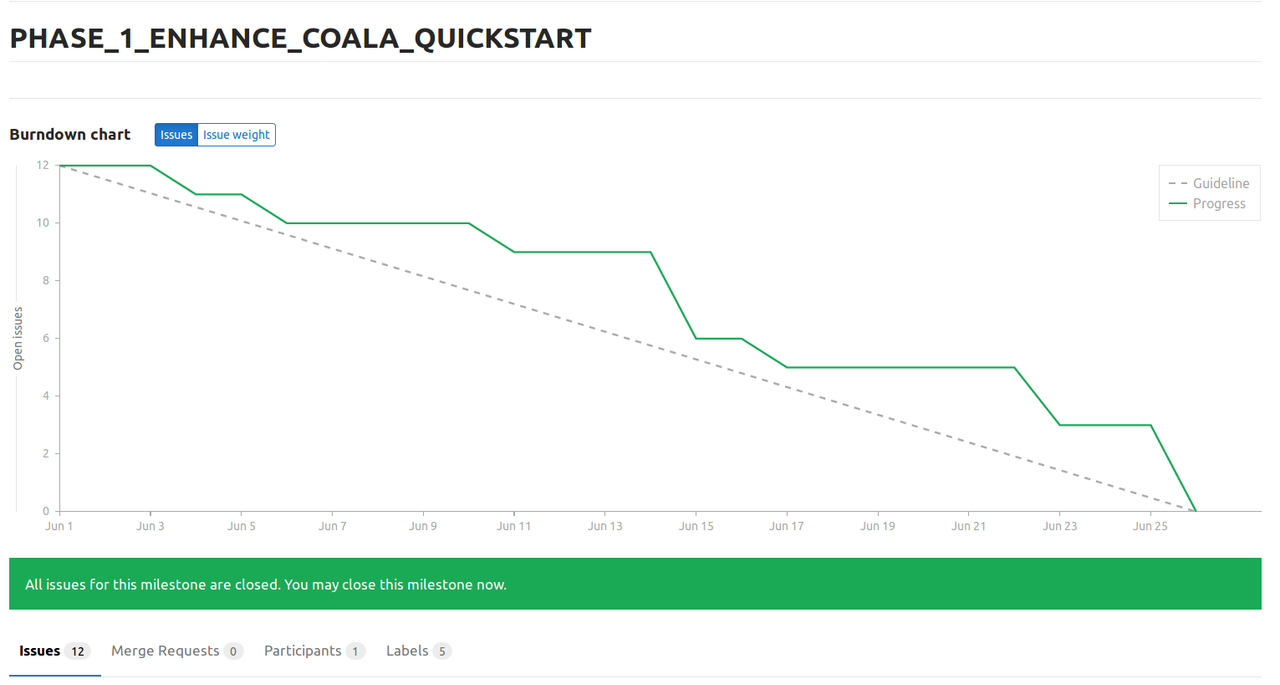
Please checkout https://gitlab.com/coala/GSoC-2017/milestones/20 to see what all tasks I worked upon during the First Phase.
This time I was more disciplined as compared to the bonding phase (the burndown chart reflects this as well :P)
So what’s next?
We planned to get a cEP (coala’s Enhancement Proposal) proposed by the end of this week and try to make a PR for GruntfileInfoExtractor, a module that extracts useful information from Gruntfile.js in projects.
As everything in this Phase needs to be designed intensively, we are planning to work on multiple tasks every week so that we keep in mind the bigger picture of how everything is going to work together at the end of the day, and reducing our chances of reaching a dead end because of immature design.
Thanks everyone for reading the post. I’m delighted to finish the first phase of my GSoC journey.
Stay tuned for more updates…
GSoC - Mid of phase 2
Published on: 09 Jul 2017, Sun
Hello world! I’m back with another post of my GSoC journey. Last week, I received an email from “Google Summer Of Code” and guess what? I passed my first evaluation : tada:.
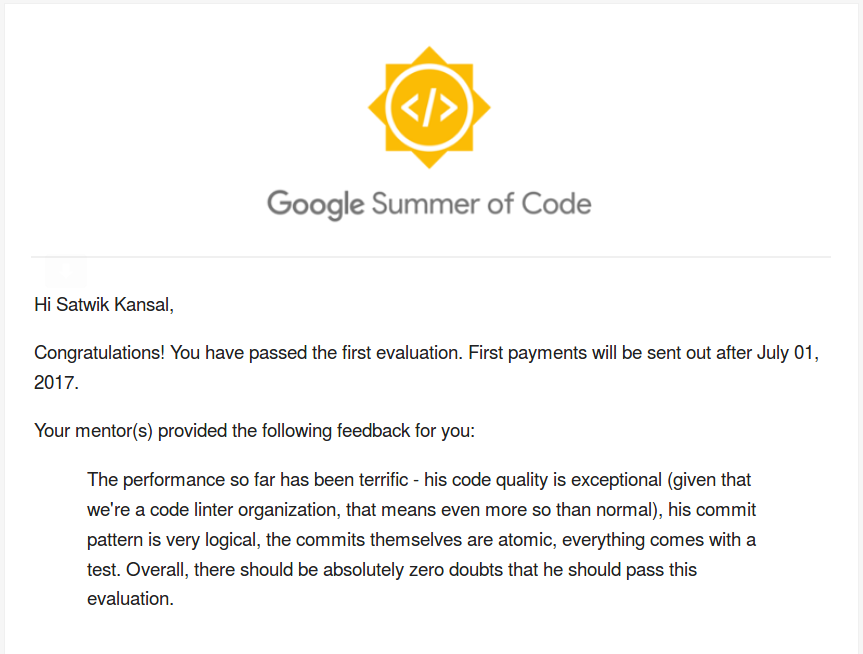
My mentors were very happy with my performance so far, and I’m really thankful for their support. Without wasting any time, I started working on the Phase 2 tasks just after submitting the Phase 1 evaluation, so coming back to my work here’s what I’ve done in the past two weeks:
TLDR;
- Proposed a cEP (coala’s Enhancement Proposal) for Information utilization process.
- Implemented and proposed a PR for
GruntfileInfoExtractor(for those who have not been following up my posts recently, anInfoExtractorclass mechanism to extract useful information from files)
Diving into the details
As I mentioned in one of my previous posts that we shifted the integration of CI from phase 2 to phase 1, so the first thing that we decided to do in this phase was to complete the remaining tasks of phase 1, i.e. GruntfileInfoExtractor. Unlike other InfoExtractor classes implemented so far, the GruntfileInfoExtractor turned out to be a bit complicated as:
- There’s no direct implementation of “Gruntfile.js” parser, so I had to make use of parse tree generated from [
pyjsparser], a pypi package for parsing JS files. - The “Gruntfile.js” has very rich API, if we were to take into consideration every possible functionality offered by “Gruntfile.js”, it’d have easily taken more than two weeks to complete it. So we tried to follow the 80-20 principle and covered the most common usage for now. Anyways, the PR is in a good state now, and I’m expecting it to get merged by the coming week after 1-2 review iterations by my mentor.
Also, we decided to dedicate some time to plan the complete bear selection and filtering framework (which, no doubt is the core of my entire GSoC project), so I tried to thoroughly document my approach in the cEP and get it validate by my mentors. This will definitely make the review process much easier both for me and my mentors.
Both Pull Requests got slightly big (~750 lines), so some decent amount of reviewing work to do by my mentor in the upcoming days.
What’s next?
This week I’ll be working to actually implement the approach discussed in the proposed cEP with proper tests and documentation and hopefully, by the end of next week, I’ll have a PR ready for the core of my GSoC project which will make us to advance a step closer to making “coala-quickstart” great again! Until then, have fun and enjoy summers!
PS: This week a lot of coala members will be meeting up at EuroPython 2017, and I really regret not being able to make it due to my campus placements coming up and some financial constraints (I spent a lot in previous Hackathons like MHacks). I still don’t know if I made a good decision or not as this event would have been an amazing learning experience for me as well, but anyways, I hope I’ll get another chance to meet the coala members in real life and a chance to speak in such a big conference very soon :)
Some nice links
The cEP I proposed - https://github.com/coala/cEPs/blob/master/cEP-0014.md
GSoC - Final Week Of Phase 2
Published on: 24 Jul 2017, Mon
Hello world! I’m back with another post of my GSoC journey. I’m into my final week of Phase 2 and will be filling out the evaluations very soon (excited!). This phase was essentially the core of my GSoC project. Here’s what I’ve done in past two weeks since my last update.
TLDR;
- Got the cEP (coala’s Enhancement Proposal) merged after review by my mentor.
- Performed a couple more iterations of my
GruntfileInfoExtractorPR and got it merged after reviews from my mentors and fellow GSoCers. - Submitted a very long PR for the actual implementation of my cEP and managed to get it merged after heavy reviews.
Here’s my burndown chart
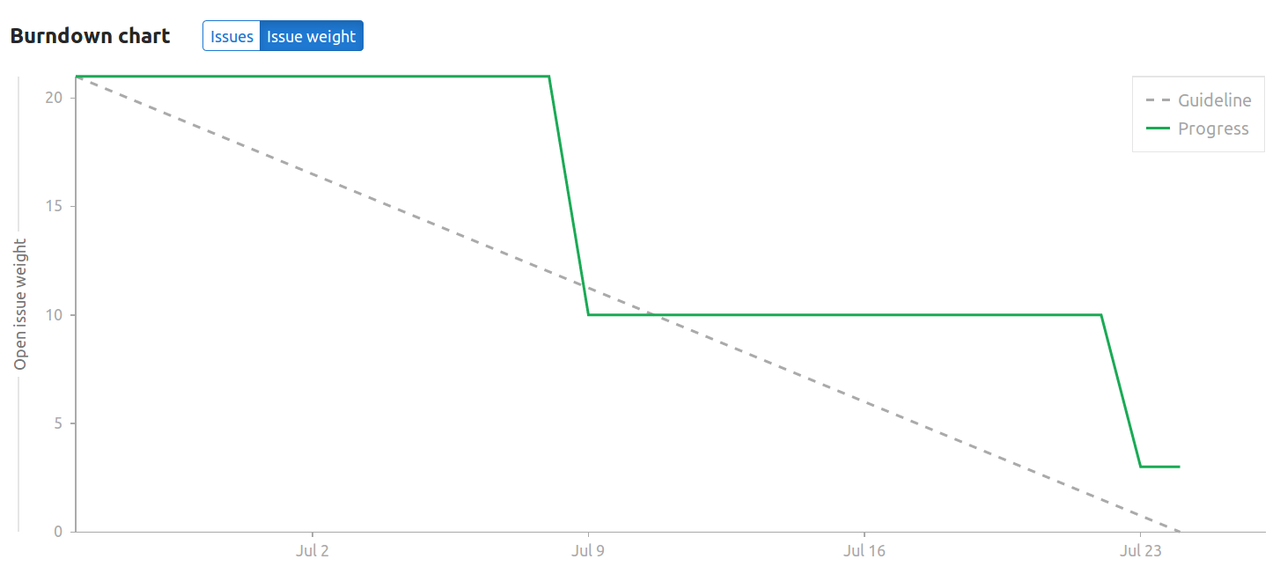
It’s pretty erratic this time because we decided to work on multiple issues a week so that we have a fair idea in mind of how everything is going to line up together to work in sync, and this is what I ended up with

PS: I realized that it’s better to manage 3-4 short PRs than one giant PR and had hard time in making changes to PR, maintaining logical order of commits, and having the all the CI services to successfully build the project with updated changes.
Diving into the details
I mentioned that GruntfileInfoExtractor PR is in good shape in my previous post, but it wasn’t! I had some silly mistakes and some code which had very high complexity be it be time complexity or cyclomatic complexity. I spent some more time to refine it after reviews and got it merged. Gruntfile.js has lot of metadata that can be useful for coala-quickstart to generate enhanced configuration file (.coafile) for coala.
My cEP implementation can be seen broadly in terms of following 3 tasks:
- Autofilling values for settings of sections in the
.coafilegenerated by coala-quickstart. Currently we use files like.editorconfigandGruntfile.jsto achieve this. Also, coala-quickstart is now able to detect inconsistency in the various configurations across such files. - Use information from dependency files (like
package.json,Gemfileandrequirements.txt) to suggest relevant information for bears. - Ask users explicitly for capabilities they want for their bears and filter bears accordingly.
The ultimate goal of coala-quickstart is “To do all the boilerplate work for coala and generate a highly relevant .coafile without minimum possible user involvement(or no inovolvement at all in the ideal case)”. After all the above three mentioned tasks implemented, we get a step closer to achieve high automation and accuracy with quickstart.
Also, coala-quickstart now works online! To try it out, go to https://coala.io/#!/coalaonline , and just enter your repository url (credits to Hemang). It’s in beta right now, so if you experience any glitches, feel free to report it here.
What’s next?
We have two choices now, either to go ahead with my proposal and make improvements to CLI and pursue some stretch goals if time allows or to further refine my work in Phase 2 and focus on “recommending relevant and useful Bears” to the users. We’ll be discussing this in next weekly meeting which is gonna happen very soon.
Thanks to Adhityaa (my primary mentor) for managing out sufficient time for the project even after his internship. Also, he has now completed his internship, and he’ll be available to help me more, but on the flip side, I’ve my campus placements starting from next week, so a lot of my time will get into studying and preparing for interviews for different companies. So it’s gonna be a big month ahead for me!!!
Anyways, I know I’ll manage it somehow, and keep you guys updated. Stay tuned for updates…
GSoC - Mid of Phase 3
Published on: 09 Aug 2017, Wed
Hey everyone! I’m back with another post describing my GSoC journey so far since the last update (released in the final week of Phase 2). Here’s all that happened since then:
- coala-quickstart broke due to some changes in the public API of coalib just before 1 day of the evaluation deadline. Thanks to John for pointing it out and reverting the changes :)
- I passed my second evaluation (yay!)
- coala-quickstart’s CLI was overwhelmed with errors related to logging and a lot of irrelevant warnings (mostly fixed now :))
- Me and Adhityaa finalized and prioritized tasks for the third phase.
- The tree became red!!! (Appveyor builds were failing due to upstream issues with lxml dependency)
- I made couple of PRs to fix un-necessary errors and warnings on the CLI.
- I made a PR adding some CLI improvements to quickstart:
- coala-quickstart will now support input validation for setting values entered by users.
- coala-quickstart now doesn’t ask users for
languagesetting values reducing the amount of information the users have to input. - Users can now enter different strings for boolean setting values. Example, coala-quickstart now will recongnize strings like “Hell yeah!!!”, “Nope”, “Definitely”, etc.
- Initiated a PR for a terminal-like autocomplete feature in quickstart’s CLI for filesystem paths.
As I mentioned in my previous post, this phase involves improvements in existing interface of coala-quickstart. I’m trying to finish all the tasks mentioned in my proposal as soon as possible and manage some time to complete some stretch goals and finally make a release of coala-quickstart :tada:
GSoC- The final week!
Published on: 22 Aug 2017, Tue
Hey everyone! I’m back with another post regarding my GSoC journey so far. This is my final week into the GSoC and I’m really glad that I made it till the end.
First of all, here’s a list of things that have done since my previous mid-phase post.
- All the warnings on the CLI are cleaned up now :)
- coala-quickstart has now this awesome feature of autocompletion for filesystem paths.
- coala-quickstart is now able to validate the input type based on the kind of settings.
- coala-quickstart can now automatically obtain setting values from
.editorconfigvalues and can even detect the inconsistency. - coala-quickstart now suggests bears based on your
Gruntfile.jscontents as well! - The new version of coala-quickstart is released now :tada: (oh yeah.. This was my first release ever!)
With all that done.. I was able to complete my project in time and everyone would be satisfied with my work I guess :)
Here’s my final submission report: https://gist.github.com/satwikkansal/b72265a0d0ec678b9291ea8e21a398ec
What’s next for coala-quickstart?
There’s still a long way to go for coala-quickstart and the most important thing to watch out for is the aspects project which will simplify the things for the users to a lot extent and will eventually open us a lot of opportunity for us to show some coala-quickstart magic.
PS: Another blog-post walking through my whole GSoC journey in brief will be coming soon and I’m trying to make it an interesting one. So until next time…